

Should You Accept A Statement If It Contains Numeric Data To Back It Up?
Exploratory Data Assay: A Practical Guide and Template for Structured Data

Very often, information technology is not the drawing that is most difficult, but rather what to draw on a blank white piece of paper that stumps people.
Similarly for information science, one may wonder how to go started subsequently receiving a dataset. This is where Exploratory Data Analysis (EDA) comes to the rescue.
According to Wikipedia, EDA "is an approach to analyzing datasets to summarize their main characteristics, often with visual methods". In my ain words, it is about knowing your data, gaining a certain amount of familiarity with the data, before one starts to extract insights from it.
Since EDA is such a crucial initial step for all data science projects, the lazy me decided to write a code template for performing EDA on structured datasets. The idea is to spend less time coding and focus more on the analysis of data itself. Scroll down to the bottom for the link to the lawmaking, merely do read on to find out more most EDA and sympathize what the lawmaking does.
Where is EDA in the Data Scientific discipline Process
Earlier we delve into EDA, information technology is important to outset get a sense of where EDA fits in the whole data science procedure.
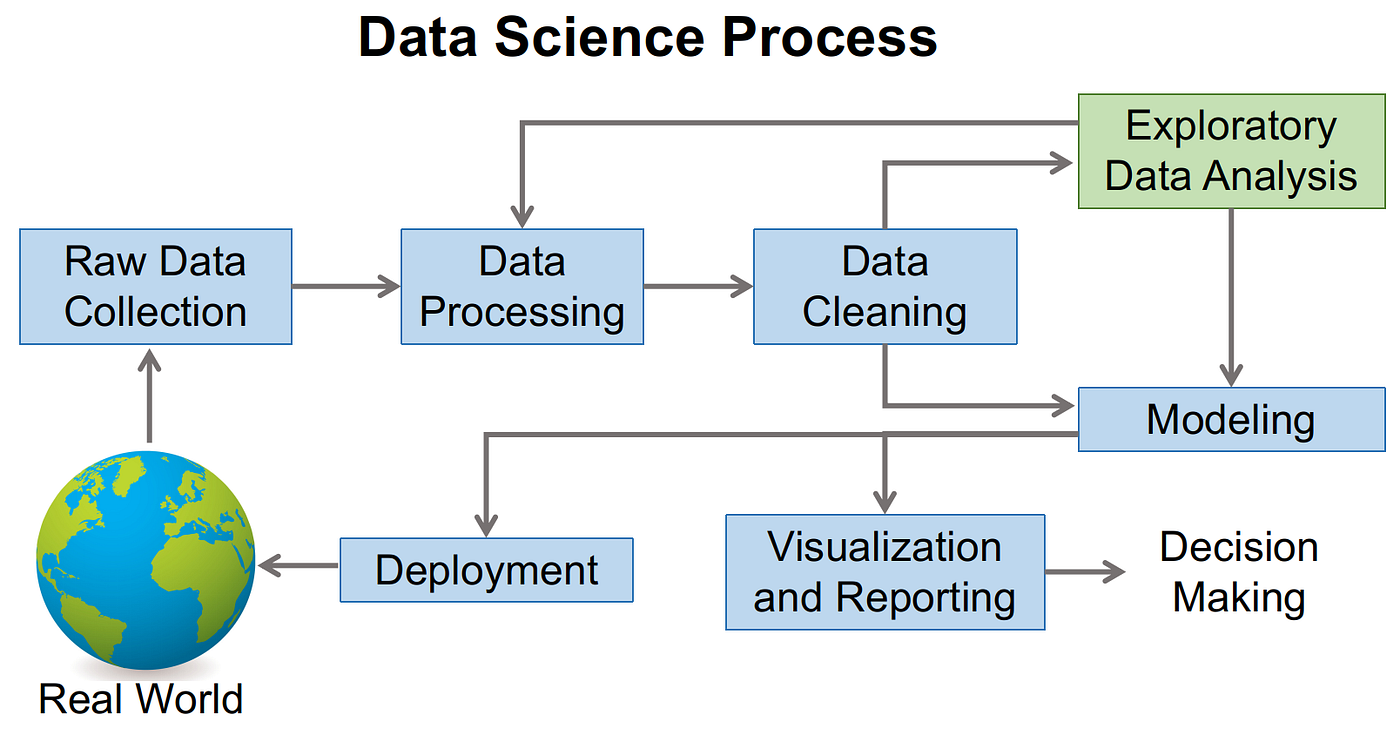
With reference to the process chart from Wikipedia, after the data has been collected, it undergoes some processing before beingness cleaned and EDA is then performed. Notice that after EDA, nosotros may go back to processing and cleaning of data, i.e., this can be an iterative process. Subsequently, we tin then use the cleaned dataset and noesis from EDA to perform modelling and reporting.
We tin, therefore, understand the objectives of EDA as such:
To gain an understanding of data and find clues from the data,
- to formulate assumptions and hypothesis for our modelling; and
- to check the quality of data for further processing and cleaning if necessary.
To improve illustrate the concept of EDA, we shall be using the Rossmann store sales "train.csv" data from Kaggle. Keeping in mind that the trouble argument is to forecast store sales, our EDA objectives are, therefore:
- To check for features that tin help in forecasting sales; and
- To check for anomalies or outliers that may affect our forecasting model.
General Outline of EDA
Our code template shall perform the post-obit steps:
- Preview information
- Bank check total number of entries and column types
- Check any nil values
- Check duplicate entries
- Plot distribution of numeric information (univariate and pairwise articulation distribution)
- Plot count distribution of chiselled data
- Analyse fourth dimension series of numeric information past daily, monthly and yearly frequencies
The necessary dependencies are as such:
import pandas as pd
import numpy every bit np
import matplotlib
import matplotlib.pyplot equally plt
import seaborn as sns
import missingno
%matplotlib inline Preliminary Data Processing
To start off, we read in our dataset and generate a simple preview and statistics of our data.
df = pd.read_csv('railroad train.csv')
df.info()
df.head() 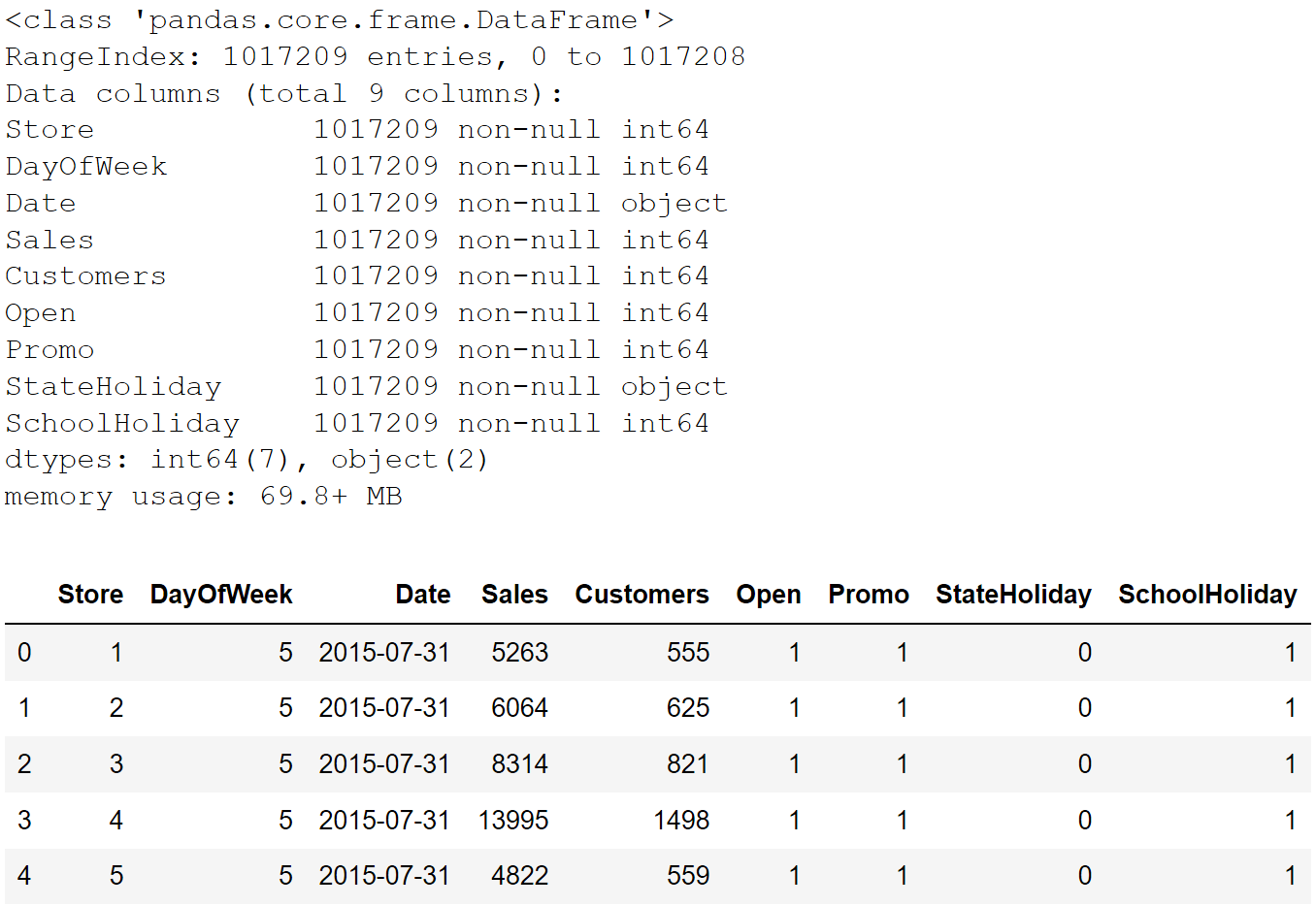
The output shows that we accept around 1 meg entries with 9 columns. No null values but some of the columns' data type should be changed. As nosotros shall run across after, setting the data types correctly can aid usa in our data science processes. In a nutshell, at that place are three common types of data type (chiselled, numeric and datetime) and nosotros take different EDA procedures for each of them.
In our preliminary processing, nosotros inverse the data types in the following way:
- Set the identifier Store every bit string.
- For columns that are categorical, i.e., columns that have on a limited, and normally stock-still, number of possible values, we set their type as "category". E.g., gender, claret type and country are all categorical data.
- For columns that are numeric, nosotros can either set their type every bit "int64" (integer) or "float64" (floating point number). E.1000., sales, temperature and number of people are all numeric data.
- Set Date as "datetime64" data type.
# set identifier "Store" as string
df['Store'] = df['Store'].astype('str') # ready categorical data
df['DayOfWeek'] = df['DayOfWeek'].astype('category')
df['Open up'] = df['Open'].astype('category')
df['Promo'] = df['Promo'].astype('category')
df['StateHoliday'] = df['StateHoliday'].astype(str).str.strip().astype('category')
df['SchoolHoliday'] = df['SchoolHoliday'].astype('category') # set up datetime information
df['Date'] = pd.to_datetime(df['Date'])
Our EDA Begins
After setting the data types, we are ready to let the fun (a.thousand.a. EDA) brainstorm.
To gear up the political party, we simply have to re-create, paste and run the code template that contains the various functions and subsequently, run the function eda that takes in a Pandas dataframe equally input.
eda(df) And that'southward it! Uncomplicated :)
Let's now become through the salient parts of the output to understand how to make use of our EDA results.
Missing values and Duplicated Entries
In our example, there is no entry with missing values.
However, in the result of missing values, the lawmaking volition generate a chart like to the one below. Discover the white spaces under CustomerID and Description; those are the missing values. Thus, in one glance, we are able to know the extent of our missing values issue.
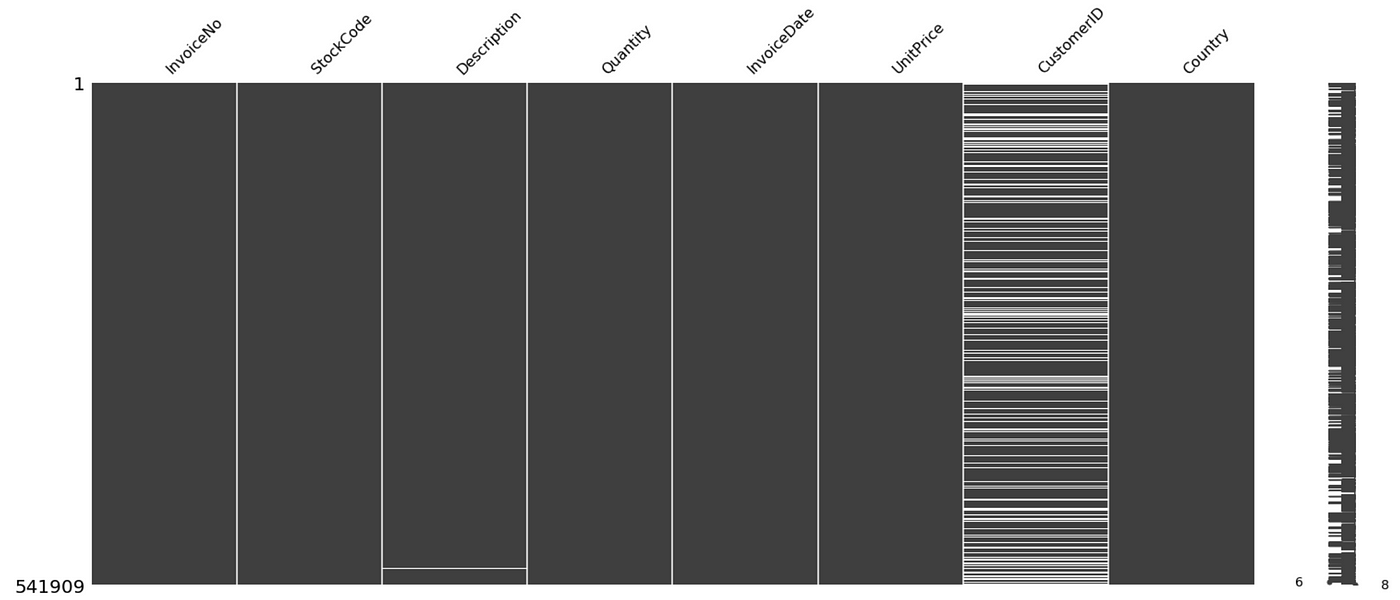
The portion of code relevant for checking missing values is as follows.
# generate preview of entries with zilch values
if df.isnull().any(axis=None):
print("\nPreview of data with null values:\nxxxxxxxxxxxxx")
print(df[df.isnull().any(axis=1)].caput(iii))
missingno.matrix(df)
plt.prove() In our example, there are besides no duplicated entries, which the code will betoken out direct by printing the output "No duplicated entries establish".
In the result of duplicated entries, the output volition show the number of duplicated entries and a preview of these entries.

Code for checking duplicated entries:
# generate count statistics of indistinguishable entries
if len(df[df.duplicated()]) > 0:
print("No. of duplicated entries: ", len(df[df.duplicated()]))
print(df[df.duplicated(keep=Simulated)].sort_values(by=listing(df.columns)).head())
else:
print("No duplicated entries found") Should in that location be any missing values or duplicated entries, you lot should decide on the cleaning steps required before proceeding further to the other parts of EDA.
For reference on how to treat missing values, you may wish to refer to this commodity by Jun Wu.
For duplicated entries, check that they are indeed duplicated and driblet them by the following code.
df.drop_duplicates(inplace=Truthful) Categorical Data EDA
Our principal EDA objective for categorical data is to know the unique values and their corresponding count.
Using the Rossmann store sales e.yard., the column Promo indicates whether a store is running a promotion on that day. Running a count of Promo by its unique values shows that promotions are held quite oftentimes, taking upwards around xl% (388,080 / 1,017,209) of store days. This may indicate that Promo is an important feature in forecasting sales.
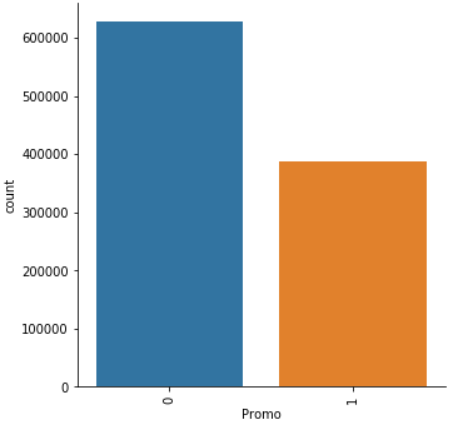
The function generating the EDA for chiselled data is categorical_eda.
def categorical_eda(df):
"""Given dataframe, generate EDA of categorical information"""
print("To bank check: Unique count of non-numeric information")
print(df.select_dtypes(include=['category']).nunique())
top5(df)
# Plot count distribution of categorical information
for col in df.select_dtypes(include='category').columns:
fig = sns.catplot(ten=col, kind="count", data=df)
fig.set_xticklabels(rotation=90)
plt.testify() Numeric Data EDA
For numeric information, our EDA approach is every bit follows:
- Plot univariate distribution of each numeric data
- If categorical data are available, plot univariate distribution by each categorical value
- Plot pairwise joint distribution of numeric data
Prior to running the eda office, we created a new cavalcade ave_sales by dividing Sales on Customers, so that we tin analyse the average sales per customer per store day.
The commencement output for our numeric data EDA shows some uncomplicated distribution statistics that include mean, standard departure and quartiles.

Some of the points that nosotros tin can derive from the output include:
- No negative values for all numeric information. If at that place is any negative value, it may mean that we have to further investigate since sales and number of customers are unlikely to be negative, and we may take to and so clean the data.
- The max values for the numeric data are quite far off from the 75 percentile, indicating that we may take outliers.
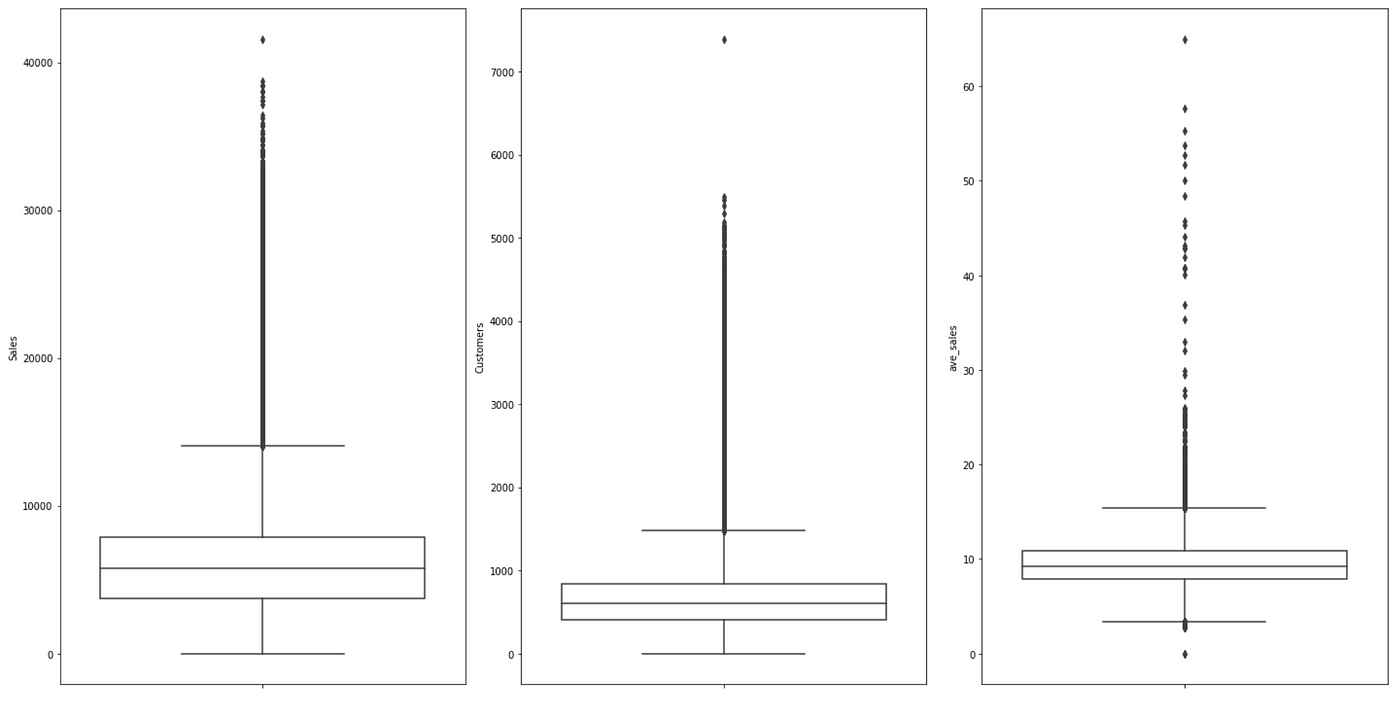
The boxplots further confirm that there is/are outlier(s) with Sales more than forty,000 or Customers greater than 7,000. We may, therefore, conduct a check to encounter if this is an error or were there other special circumstances leading to the exceptional figures.
We have also plotted violin plots for each numeric data past category values to investigate for due east.m., the effect of Promo on Sales.
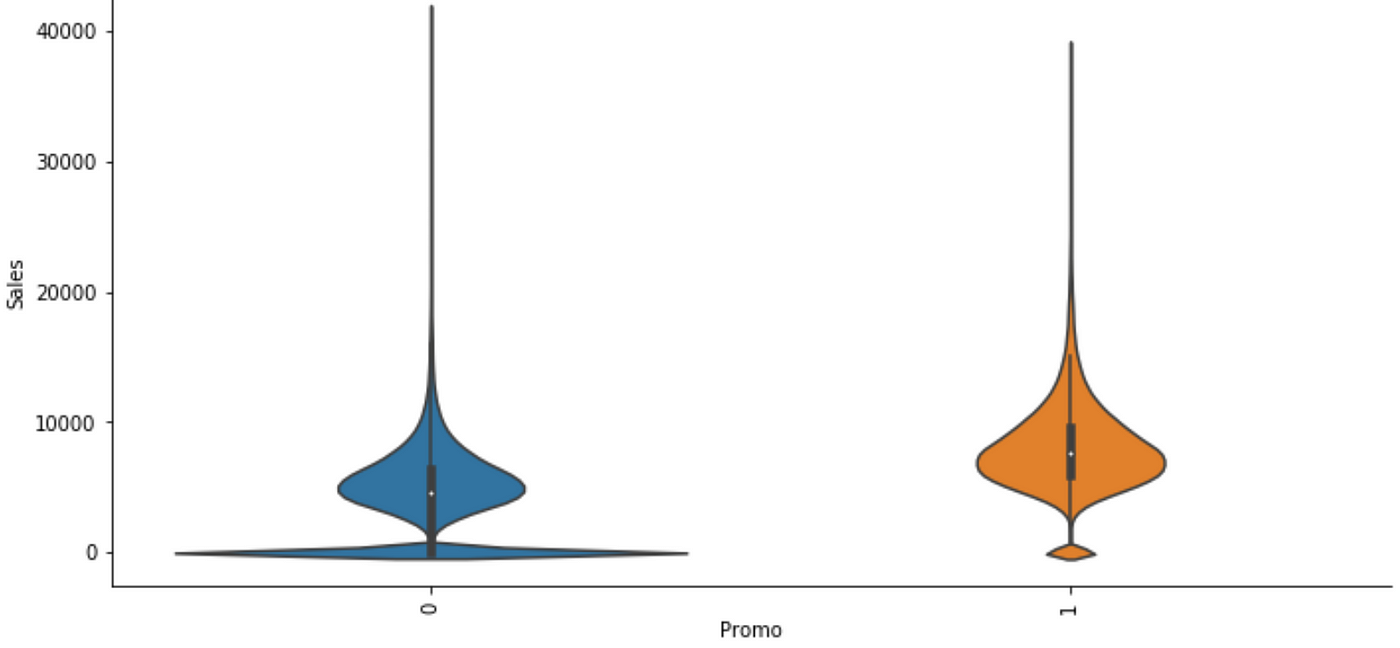
From the violin plot above, we tin infer that on days of promotion, sales typically increase as seen from the wider sections of the violin plot. The wide section of the plot near 0 Sales for Promo=0 is probably due to closed stores. Running the eda part again later afterwards removing entries with Open up=0 shows that the wide section virtually 0 is no longer present, thereby confirming our hypothesis.
The last output for numeric data EDA is a pairwise joint distribution plot.
To generate farther insights, we ran the role numeric_eda and added a parameter hue='DayOfWeek'. This allows usa to color our pairwise plot by each day of the week.
numeric_eda(df, hue='DayOfWeek') 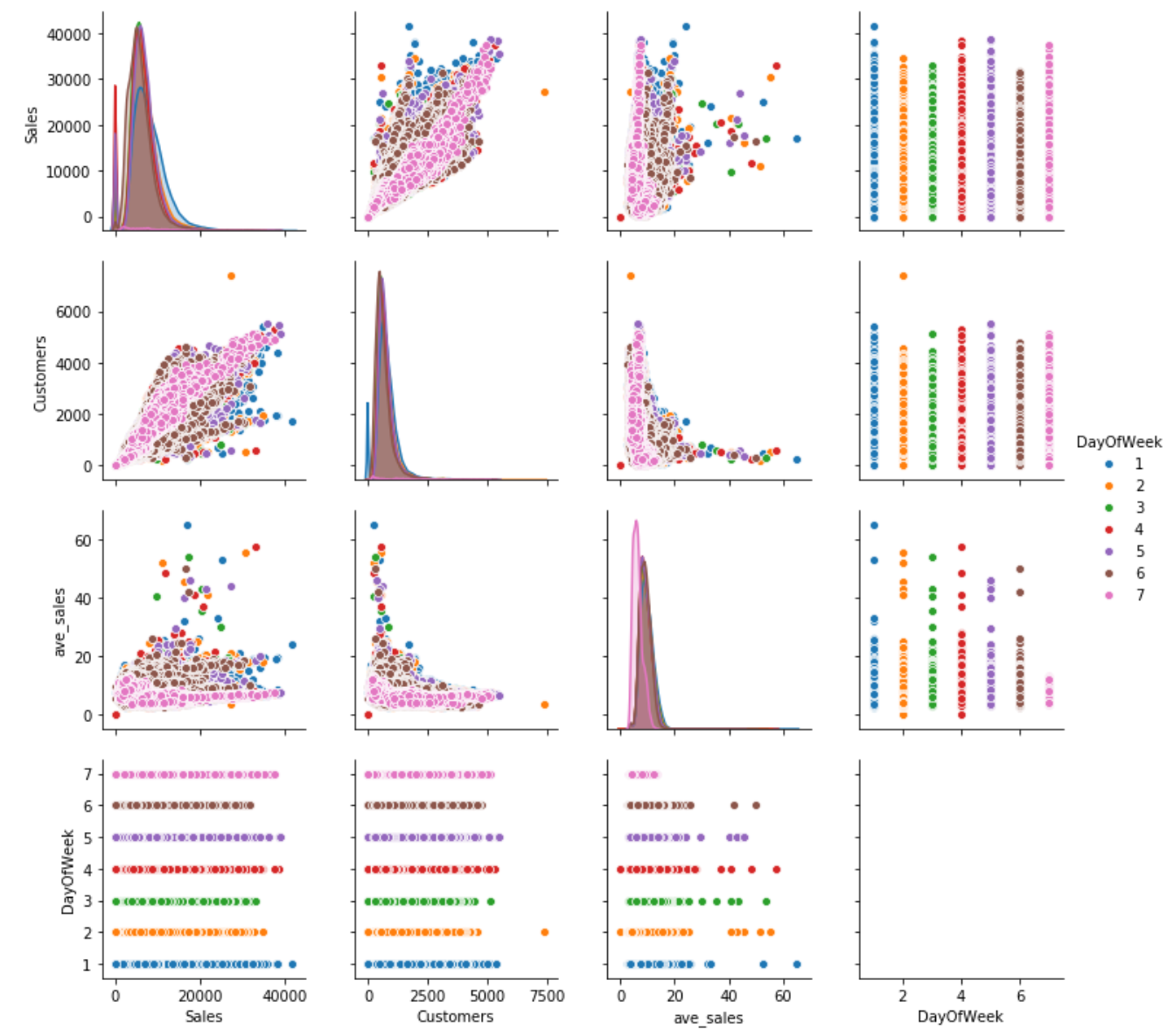
By incorporating the DayOfWeek into the plot, we noticed that Dominicus'southward ave_sales (represent past pinkish color) is relatively more abiding than the other days. This is, therefore, something that can be further investigated and considered every bit a predictor.
Time series EDA
Lastly, we also plotted time serial charts to check for trends and seasonality.
For ease of analysis, our code automatically sums upward the numeric data past daily, monthly and yearly frequency earlier plotting the charts. Information technology achieves this through Pandas' resample method.
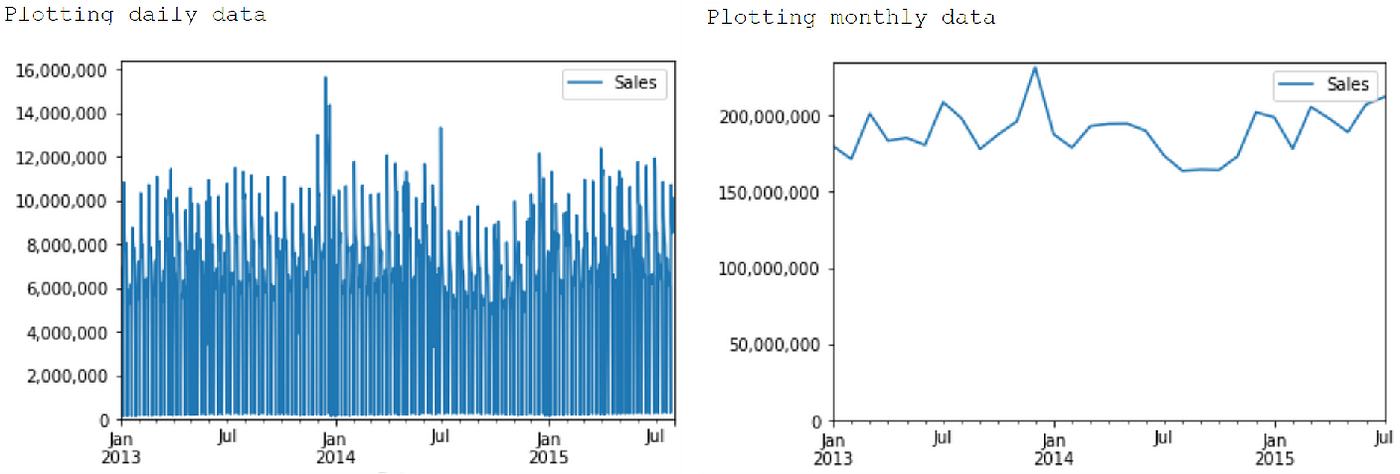
In our case, the yearly chart is not useful equally the data only contains partial 2015 information, hence we accept left information technology out from the screenshots.
From the daily plot, we can see that there are outliers towards the end of December 2013. This is likewise reflected in the monthly plot.
The monthly plot besides shows that in that location is some seasonality, namely lower sales in Feb that is probably due to short month effect, as well equally higher sales towards end of year. If we are predicting monthly sales, our forecasting would accept to have this seasonality effect into consideration.

Should You Accept A Statement If It Contains Numeric Data To Back It Up?,
Source: https://towardsdatascience.com/exploratory-data-analysis-eda-a-practical-guide-and-template-for-structured-data-abfbf3ee3bd9
Posted by: hubertimas1991.blogspot.com
0 Response to "Should You Accept A Statement If It Contains Numeric Data To Back It Up?"
Post a Comment